How to use Jina NOW’s CLI and API#
Use CLI Parameters#
Instead of answering the questions in the CLI dialog manually, you can also provide command-line arguments when starting Jina NOW as shown here.
jina now start --dataset-type "DocumentArray name" --dataset-name "my-documentarray-id" --index-fields "title" [...]
Use the Jina Client#
When you have successfully deployed your application, you can send requests to the deployment using the Jina client. To do this,
use the gateway that you received upon deploying your app. It will look similar to this:
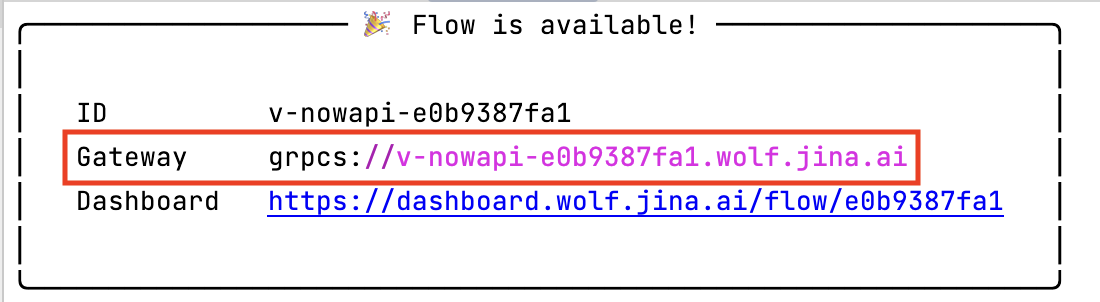
Check Liveness#
To see whether your application is available and running, simply send a request on the /ping endpoint using the gateway
provided to you upon deployment of the app.
from jina import Client
client = Client(
host='grpcs://now-example-bird-species.dev.jina.ai&data=bird-species' # add your own gateway here
)
response = client.post(on='/ping')
assert response.status_code == 200 # successful response!
Search requests#
To make a search request using the Jina client, we need to formulate our query as a docarray.Document. Below
is an example of such a document.
from docarray import Document, dataclass
from docarray.typing import Text, Image
from jina import Client
# formulating a multimodal query
@dataclass
class Query:
text: Text
image: Image
query_doc = Document(Query(text='cat', image='<example-image-uri>.png'))
client = Client(
host='grpcs://now-example-bird-species.dev.jina.ai&data=bird-species' # add your own gateway here
)
response = client.search(
query_doc,
parameters={'limit': 9, 'filters': {}},
)
assert len(response) == 9
Similarly, you can access the other endpoints such as /suggestion and /list.
Use the API#
If you prefer making post requests directly to the API, you can take a look at the documentation link supplied to you when deploying your application:

Requests should be made to ‘https://nowrun.jina.ai/api/v1/search-app/’, which hosts the backend for frontend (BFF), exposing all important endpoint that you can integrate into your frontend.
Below we will cover some example requests to the endpoints.
Search requests#
Search requests can be formulated as follows:
curl -X "POST" \
"https://nowrun.jina.ai/api/v1/search-app/search" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d "{
'host': 'grpcs://v-nowapi-e0b9387fa1.wolf.jina.ai',
'port': '443',
'query': [
{'name': 'query_text', 'value': 'black dress', 'modality': 'text'},
{'name': 'query_image', 'value': '<insert_image_uri>', 'modality': 'image'},
],
'limit': '5',
'filters': {},
'get_score_breakdown': true,
}"
Make sure to grab the host from the CLI deployment print as shown in the previous section.
As for the query, the BFF allows you to send multimodal queries in the form of a list, where each item in the list
consists of a dictionary in the following form:
{
'name': 'query_text', # defining the name of your query field
'value': 'cute cat', # the query itself, consisting of text of image
'modality': 'text', # the modality of the query, options: 'image' OR 'text'
}
Optional parameters:
limit: set the number of results in the response
example:
5
filters: a dictionary of filters, with filter name as key and target as value. The target should be a list of strings in the case of categorical filters, and a dictionary with operators as keys and floats or integers as values in the case of numerical filters. See the Elasticsearch documentation for more information on range queries and allowed operators.
example:
{'tags__color': ['blue'], 'tags__price': {'gt': 100, 'lte': 200}}
score_calculation: list of score calculation components defining how fields should be compared and weighted. Each score calculation must contain 4 items, the query field and index field, the encoding model used to create representations for both fields, and the weight this score should have in the overall calculation, ranging between 0 and 1. You can also add a bm25 score, replacing the encoding model with the string
'bm25'as shown in the example.example:
[['query_text', 'title', 'encodersbert', 1.0], ['query_text', 'description', 'bm25', 0.5]]
get_score_breakdown: boolean indicating whether to return the score breakdown for each result document. Scores are returned as a dictionary with the key being the name of the score (example:
'query_text-title-encodersbert-1.0') and the value being adocarray.score.NamedScore.example:
true
Cleanup#
jina now stop
Requirements#
LinuxorMacPython 3.7,3.8,3.9or3.10
